Week 1 - Fine-tuning LLMs with instruction
In contrast to pre-training, where you train the LLM via self-supervised learning, Fine-tuning is a supervised learning process where you used a data set of labeled examples to update the weights of the LLMs
- Full fine-tuning (updates all parameters)
- Instruction fine-tuning
parameter efficient fine-tuning or PEFT
PEFT is a set of techniques that preserves the weights of the original LLM and trains only a small number of task-specific adapter layers and parameters. PEFT shows greater robustness to catastrophic forgetting since most of the pre-trained weights are left unchanged. PEFT is an exciting and active area of research that we will cover later this week. In the meantime, let’s move on to the next video and take a closer look at multitask fine-tuning.
Fine-tuning for multitasks
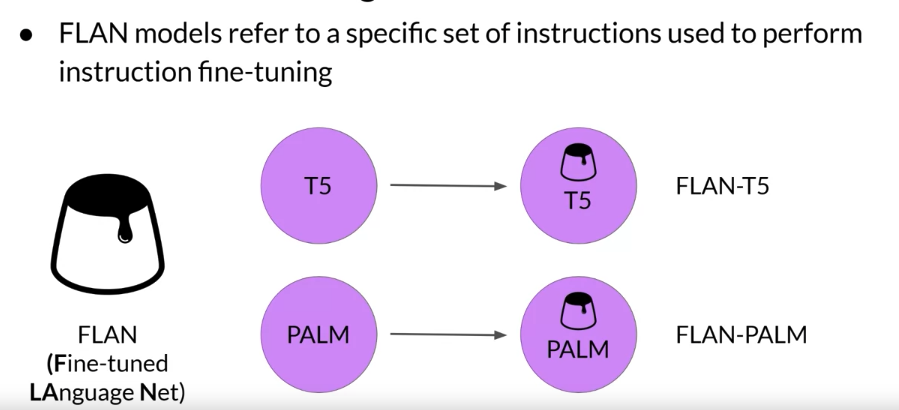
FLAN family (Fine-tuned LAnguage Net)
FLAN, which stands for fine-tuned language net,
is a specific set of instructions used to fine-tune different models.
LoRA
because of the performance results of using those low rank matrices as opposed to full fine-tuning